
How Much Better is Imagen to DALL-E 2?
The text-to-image A.I. arms race is getting wet, heated and unreal.


Hey Guys,
DeepMind is showing it’s superiority here.
Google’s Imagen application would allow you to type in the phrase like, say, “a blue jay standing on a large basket of rainbow macarons” (a real example they use) and get back a photorealistic depiction of your sentence.
https://arxiv.org/abs/2205.11487
Check out the video for quick tl;dr.
AI can unlock joint human/computer creativity!
Imagen is one direction we are pursuing:
https://gweb-research-imagen.appspot.com
On May 23rd, 2022 Google announced its own take on the genre, Imagen, and it just unseated DALL-E in the quality of its output.
To assess text-to-image models in greater depth, we introduce DrawBench, a comprehensive and challenging benchmark for text-to-image models. With DrawBench, we compare Imagen with recent methods including VQ-GAN+CLIP, Latent Diffusion Models, and DALL-E 2, and find that human raters prefer Imagen over other models in side-by-side comparisons.
There you have it Imagen > DALL-E 2.

Any Dangers?

Google Imagen is so controversial it doesn’t even have a demo and the code wasn’t released publically.
Limitations and Societal Impact
There are several ethical challenges facing text-to-image research broadly.
First, downstream applications of text-to-image models are varied and may impact society in complex ways.
The potential risks of misuse raise concerns regarding responsible open-sourcing of code and demos.
Second, the data requirements of text-to-image models have led researchers to rely heavily on large, mostly uncurated, web-scraped datasets. While this approach has enabled rapid algorithmic advances in recent years, datasets of this nature often reflect social stereotypes, oppressive viewpoints, and derogatory, or otherwise harmful, associations to marginalized identity groups.
While a subset of our training data was filtered to removed noise and undesirable content, such as pornographic imagery and toxic language, we also utilized LAION-400M dataset which is known to contain a wide range of inappropriate content including pornographic imagery, racist slurs, and harmful social stereotypes.
Imagen relies on text encoders trained on uncurated web-scale data, and thus inherits the social biases and limitations of large language models. As such, there is a risk that Imagen has encoded harmful stereotypes and representations, which guides our decision to not release Imagen for public use without further safeguards in place.
While we leave an in-depth empirical analysis of social and cultural biases to future work, our small scale internal assessments reveal several limitations that guide our decision not to release our model at this time.
Imagen, may run into danger of dropping modes of the data distribution, which may further compound the social consequence of dataset bias. Imagen exhibits serious limitations when generating images depicting people. Our human evaluations found Imagen obtains significantly higher preference rates when evaluated on images that do not portray people, indicating a degradation in image fidelity.
Preliminary assessment also suggests Imagen encodes several social biases and stereotypes, including an overall bias towards generating images of people with lighter skin tones and a tendency for images portraying different professions to align with Western gender stereotypes.
Finally, even when we focus generations away from people, our preliminary analysis indicates Imagen encodes a range of social and cultural biases when generating images of activities, events, and objects. We aim to make progress on several of these open challenges and limitations in future work.
As such Google didn’t release the code open-source or release a working demo.

While the headlines are impressive and the Blog is painting Google in the best possible light, the news reviews of Image weren’t very positive. The Verge for instance, reminded us that when research teams like Google Brain release a new AI model they tend to cherry-pick the best results.
Imagen starts by generating a small (64×64 pixels) image and then does two “super resolution” passes on it to bring it up to 1024×1024.
Google’s key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model.
All in all that is pretty interesting.
Authors
Chitwan Saharia*, William Chan*, Saurabh Saxena†, Lala Li†, Jay Whang†, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho†, David Fleet†, Mohammad Norouzi*
*Equal contribution. †Core contribution.
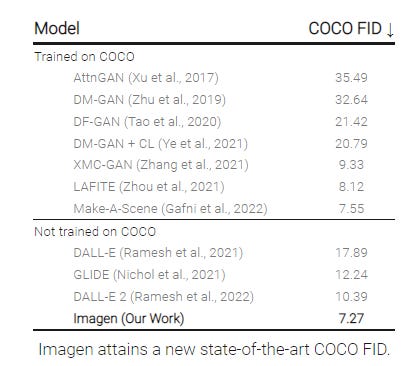
Imagen achieves a new state-of-the-art FID score of 7.27 on the COCO dataset, without ever training on COCO, and human raters find Imagen samples to be on par with the COCO data itself in image-text alignment.
Google Warns us:
Imagen relies on text encoders trained on uncurated web-scale data, and thus inherits the social biases and limitations of large language models. As such, there is a risk that Imagen has encoded harmful stereotypes and representations, which guides our decision to not release Imagen for public use without further safeguards in place.
By Google’s side however there’s always a place for royalty.

Google, though, claims that Imagen produces consistently better images than DALL-E 2, based on a new benchmark it created for this project named DrawBench.
Google’s literature seemed partly based on why Imagen is better than older solutions (April, 2022) such as DALL-E 2.

According to Google, humans prefer Imagen, strongly even.
Google isn’t making the Imagen model available to the public, so it’s difficult to judge anything for ourselves here, even Google’s claims that its Imagen is embedded with bias, sterotypes, racism and so forth.
I don’t know about you guys, but I find it all a bit absurd. Including how limited DrawBench was for the side to side comparisons.
I felt like a pretty sad racoon reading their blog.

Thanks for reading guys!