
What is DeepSpeed?
Microsoft Research produces something interesting in 2022.

DeepSpeed is an open source deep learning optimization library for PyTorch. The library is designed to reduce computing power and memory use and to train large distributed models with better parallelism on existing computer hardware.
Its Stable release was on January 14th, 2022. That’s one week ago today. DeepSpeed was made specially at Microsoft Research.
The DeepSpeed team, as part of Microsoft’s AI at Scale initiative, has been exploring new applications and optimizations for MoE models at scale. These can lower the training and inference cost of large models, while also enabling the ability to train and serve the next generation of models affordably on today’s hardware.
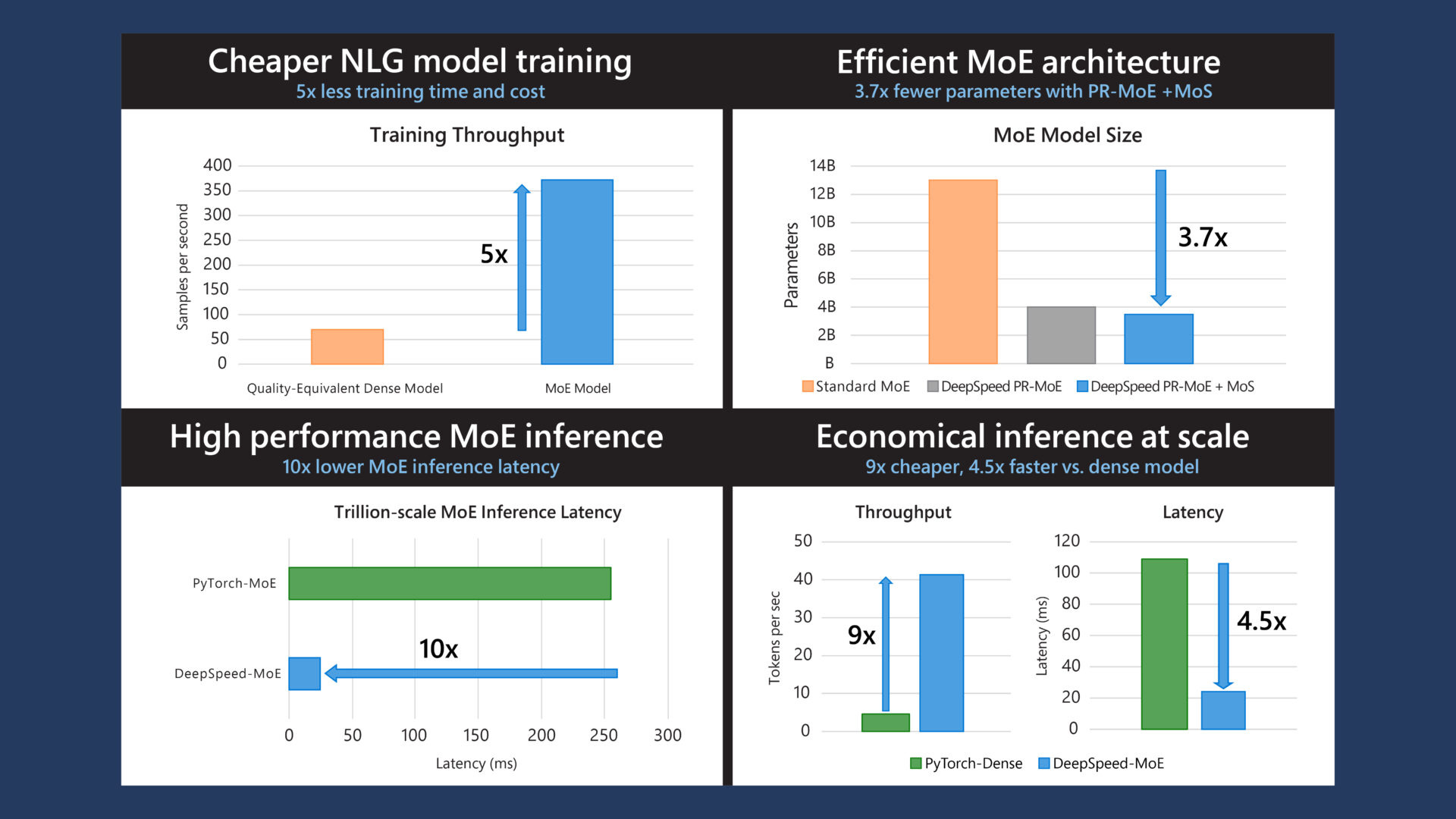
The DeepSpeed-MoE (DS-MoE) inference system enables efficient scaling of inference workloads on hundreds of GPUs, providing up to 7.3x reduction in inference latency and cost when compared with existing systems, according to their blog.
DeepSpeed is Open-Source
Microsoft Research February, 2021 announced DeepSpeed, an open-source deep learning training optimization library, and ZeRO (Zero Redundancy Optimizer), a novel memory optimization technology in the library, which vastly advances large model training by improving scale, speed, cost, and usability.
DeepSpeed is thus a deep learning optimization library that makes distributed training easy, efficient, and effective.
It can train DL models with over a hundred billion parameters on the current generation of GPU clusters while achieving over 5x in system performance compared to the state-of-art.
Early adopters of DeepSpeed have already produced a language model (LM) with over 17B parameters called Turing-NLG, establishing a new SOTA in the LM category.
DeepSpeed is a tool in the Machine Learning Tools category of a tech stack.
DeepSpeed is an open source tool with 6.1K GitHub stars and 695 GitHub forks. Here’s a link to DeepSpeed's open source repository on GitHub
You can check out the DeepSpeed website here.
Paper: https://arxiv.org/pdf/2201.05596.pdf
Github: https://github.com/microsoft/DeepSpeed
MarketTech also wrote a piece on it that’s good.
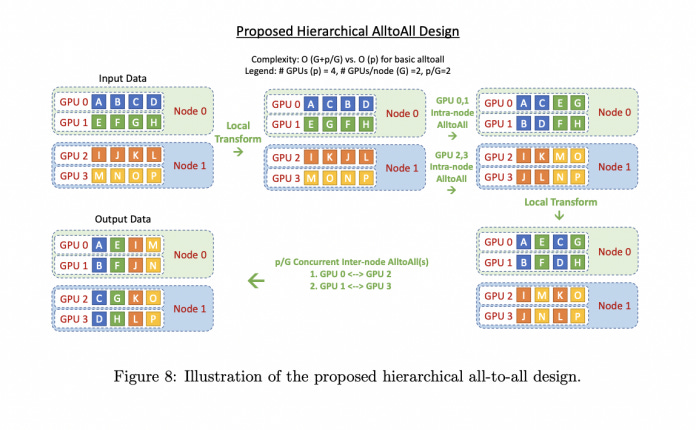
Source: https://arxiv.org/pdf/2201.05596.pdf
Key Takeaways
Microsoft’s DeepSpeed-MoE precisely meets this requirement, allowing Massive MoE Model Inference to be performed up to 4.5 times faster and nine times cheaper.
Microsoft Research sees DeepSpeed as an important component of AI at Scale.
More specifically, DeepSpeed adds four new system technologies that further the AI at Scale initiative to innovate across Microsoft’s AI products and platforms. These offer extreme compute, memory, and communication efficiency, and they power model training with billions to trillions of parameters.
DeepSpeed is PyTorch Compatible Library for AI at Scale
Microsoft’s AI at Scale initiative is pioneering a new approach that will result in next-generation AI capabilities that are scaled across the company’s products and AI platforms.
DeepSpeed is a PyTorch-compatible library that vastly improves large model training by improving scale, speed, cost and usability—unlocking the ability to train models with over 100 billion parameters.
One piece of the DeepSpeed library, ZeRO 2, is a parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained.
With DeepSpeed Microsoft Resarchers claimed to achieve up to a 6.2x throughput improvement, 2.8x faster convergence, and 4.6x less communication.
DeepSpeed has enabled researchers to create Turing Natural Language Generation (Turing-NLG), the largest language model with 17 billion parameters and state-of-the-art accuracy at the time of its release.
In May, 2021 they released ZeRO-2—supporting model training of 200 billion parameters up to 10x faster compared to state of the art—along with a list of compute, I/O, and convergence optimizations powering the fastest BERT training.
3D Parallelism
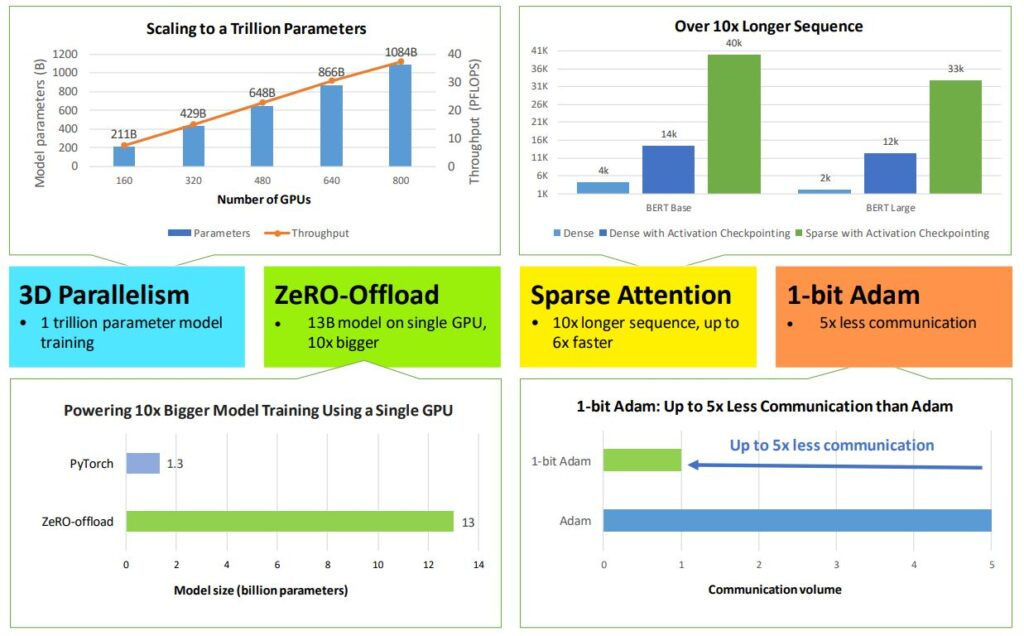
DeepSpeed enables a flexible combination of three parallelism approaches—ZeRO-powered data parallelism, pipeline parallelism, and tensor-slicing model parallelism. 3D parallelism adapts to the varying needs of workload requirements to power extremely large models with over a trillion parameters while achieving near-perfect memory-scaling and throughput-scaling efficiency.
In addition, its improved communication efficiency allows users to train multi-billion-parameter models 2–7x faster on regular clusters with limited network bandwidth.
They extend ZeRO-2 to leverage both CPU and GPU memory for training large models.
This feature democratizes multi-billion-parameter model training and opens the window for many deep learning practitioners to explore bigger and better models. Read the paper: https://www.microsoft.com/en-us/research/publication/zero-offload-democratizing-billion-scale-model-training/
DeepSpeed Sparse Attention
DeepSpeed offers sparse attention kernels—an instrumental technology to support long sequences of model inputs, whether for text, image, or sound. Compared with the classic dense Transformers, it powers an order-of-magnitude longer input sequence and obtains up to 6x faster execution with comparable accuracy.
They claim this powers 10x longer sequences and 6x faster execution through.
If you enjoyed this article consider following my AI Newsletter as well:
Otherwise I hope this gave you a satisfactory introduction to what DeepSpeed is what why it is important in the scalability of AI and larger models. If you want to support my work I would super appreciate it as I cannot continue to write without significant community or corporate partners.