

Meta AI's Incredible early-stage AI translation tool
More data on languages for Universal Translation is only a good thing.


JULY 7, 2022
Hey Guys,
Welcome to Data Science Learning Center Premium,
This is a new Column called Business Science Center.
I was impressed this week about Meta AI’s contribution to Universal Translation for over 200 languages powered by their supercomputer.
Meta AI has quite a few interesting projects of late where this AI model is part of an ambitious R&D project by Meta to create a so-called “universal speech translator,” which the company sees as important for growth across its many platforms — from Facebook and Instagram, to developing domains like VR and AR.
In the next decade who knows we may be communicating with people from anywhere in the world in the Metaverse with such UST tech.
The 200 (actually 204)
Six months ago, the company launched its ambitious No Language Left Behind (NLLB) project, training AI to translate seamlessly between numerous languages without having to go through English first. On Wednesday, the company announced its first big success, dubbed NLLB-200.
The paper is downloadable in a PDF form of around 190 pages. Here: https://research.facebook.com/publications/no-language-left-behind
Meta also shares the model on GitHub open-source.
The Verge speculates that this kind of machine translation not only allows Meta to better understand its users (and so improve the advertising systems that generate 97 percent of its revenue) but could also be the foundation of a killer app for future projects like its augmented reality glasses.
I outgrew the conglomerate’s suite of apps many moons ago, but the Metaverse awaits. I just hope we’ll see Universal Language Translation embedded everywhere in ambient computing sooner rather than later.

A.I. for Good and Inclusion
“The major contribution here is data,” Professor Alexander Fraser, an expert in computational linguistics at LMU Munich in Germany. “What is significant is 100 new languages [that can be translated by Meta’s model].”
Meta’s model seems to get better at some of the trickier languages of the world as well. NLLB-200 can translate 55 African languages with “high-quality results.” Meta boasts that the model’s performance on the FLORES-101 benchmark surpassed existing state-of-the-art models by 44 percent on average, and by as much as 70 percent for select African and Indian dialects.

Meta has decided to open-source NLLB-200 as well as provide $200,000 in grants to nonprofits to develop real-world applications for the technology.
►Meta’s Video:
►Research paper: https://research.facebook.com/publications/no-language-left-behind
►Code: https://github.com/facebookresearch/fairseq/tree/nllb
►My Newsletter: What is No Language Left Behind?
Here is the Abstract of the Paper:
Abstract
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety.
“Translation doesn’t even work for the languages we speak, so that’s why we started this project,” said Angela Fan. “We have this inclusion motivation of like — ‘what would it take to produce translation technology that works for everybody’?”
Montreal based A.I. influencer Louis Bouchard wrote a nice paper about it.
To evaluate the quality of the new model’s output, Meta created a test dataset consisting of 3001 sentence-pairs for each language covered by the model, each translated from English into a target language by someone who is both a professional translator and native speaker.
The researchers ran these sentences through their model, and compared the machine’s translation with the human reference sentences using a benchmark common in machine translation known as BLEU (which stands for BiLingual Evaluation Understudy).
You can get a sense of how the new model works on Meta’s demo site.
The project was also said to be somewhat limited:
Christian Federmann, a principal research manager who works on machine translation at Microsoft, said the project as a whole was “commendable” in its desire to expand the scope of machine translation software to lesser-covered languages, but noted that BLEU scores by themselves can only provide a limited measure of output quality.
ARE THERE POWER IMBALANCE IN CORPORATE AI?
The Verge pointed out an interesting take on the real inclusiveness of many A.I. for good projects. For example, working on AI translation is often presented as an unambiguous good, but creating this software comes with particular difficulties for speakers of low-resource languages. For some communities, the attention of Big Tech is simply unwelcome (Wired): they don’t want the tools needed to preserve their language in anyone’s hands but their own.
So while Meta’s initiative is obviously good, there are various technical imitations in the study and ethical challenges in what they are trying to accomplish.
Meta’s engineers explored some of these questions by conducting interviews with 44 speakers of low-resource languages.
I have to wonder if Meta’s boasting is really a good thing though.
204 - The company claims that the AI supports more languages and provides higher-quality translations than world-leading software. The model, called No Language Left Behind, supports dozens more text-based languages than Google Translate, which currently works for 133, and Microsoft Translator, which caters for 110.
According to Meta, the new model beat existing benchmarks by as much as 70 percent. This is getting into DeepMind and OpenAI territory of hype creation, where PR is taking over from the real value of the research. Yes Meta, we know you want to create good hype for your new name and brand.
The Power of Language
Language is not only a way for people to communicate with one another, but it also conveys culture, history, and self-identity (Demichelis and Weibull, 2008; Hall, 2013).

Meta’s 190 PDF paper actually has a lot of fascinating info on how language drives human beings. Even though many of our low-resource language interviewees are also fluent English speakers, almost all of them maintain that their native tongue remains a foundational part of their identity.
Even though many of our low-resource language interviewees are also fluent English speakers, almost all of them maintain that their native tongue remains a foundational part of their identity.
Meta tried to improve data for more marginalized and less common languages, known under the broad definition of low-resource languages.
Over 7000 languages are spoken across the world today. Meta only really worked on 204.

Figure 3: Human-Translated Dataset Contributions of No Language Left Behind: As highlighted, these datasets enable model training and evaluation.


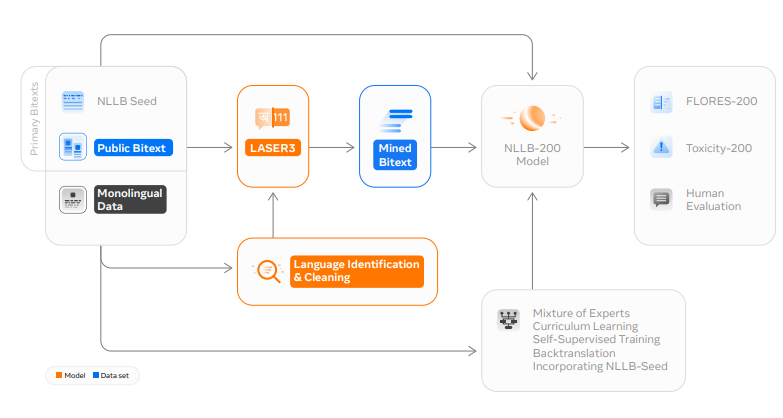
Figure 6: Automatic Dataset Creation Contributions of No Language Left Behind: As highlighted, we create language identification and a monolingual data cleaning process, then describe the training of LASER3 to produce large-scale mined bitext for hundreds of languages.
Thanks for reading!
DOWNLOAD the PDF.
Thanks for being one of over 20+ paying subscribers who supports this channel.